
Hello and welcome back to our (hopefully) exciting series about network penetration testing!
The ultimate goal of a penetration test is often to find sensitive or personally identifying information; otherwise, the goal may be to expose security vulnerabilities that would allow this type of content to be accessed without authorization. Ethical hacking can be fun, but we must remain cognizant of our goals.
If you missed the first part of this series, take the time to read it and familiarize yourself with where we are at this point. You will need to be caught up, because today we are putting our virtual cross hairs on specific targets we want to attack.
Ready, aim…
As a reminder of what we have covered thus far, we first used a combination of the nmap and Eyewitness tools to scan our network for open ports. Then, we gathered a considerable amount of information about those open ports and carved it down into a clean, easy-to-read Web page format.
The next step is to start going through these results and see if we can find some “interesting” targets to attack. (Note: the system in this demonstration is intentionally configured to be vulnerable – I’ll revisit this later and show you how you can easily setup your own test systems to safely hammer away on.)
Here is a screenshot for a system on my network that appears to be running some sort of Web service:
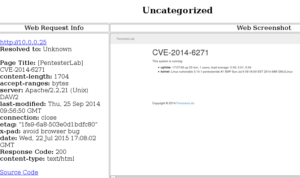
Crawl the content
When you come across a site in the real world that you suspect may hold interesting content or vulnerabilities, one of the first and easiest things you can do is “crawl” it. Crawling is essentially automating the process of clicking through all the various links and mapping out the site structure for further investigation. One way to do this is by using a command line tool called dirb (which is built right into Kali Linux) like so:
dirb http://10.0.0.25 /usr/share/wordlists/dirb/big.txt
Here’s the breakdown of the commands:
- dirb – calls the dirb tool into action!
- http://10.0.0.25 – this is the website we’re going to crawl
- /usr/share/wordlists/dirb/big.txt – this points to the word list that we will use for crawling.
So when dirb kicks off, it is going to crawl the structure of the 10.0.0.25 website and use the big.txt word list to look for files and folders that may not be directly linkable. For example, dirb will try finding folders such as:
- http://10.0.0.25/admin
- http://10.0.0.25/administrator
- http://10.0.0/25/login
- http://10.0.0.25/hidden
- http://10.0.0.25/secret
- …and so on..
Lets take a look at what dirb was able to produce:
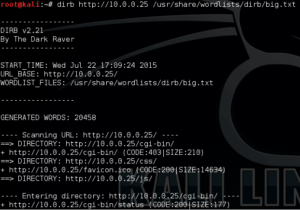
As you can see, dirb has located a URL called http://10.0.0.25/cgi-bin/status that looks interesting. When we pull that up in a browser:

This is some sort of status message that may reveal sensitive information about the system or a foothold we can use for further exploitation. When in doubt, Google is always our friend:
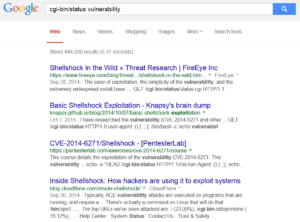
Aha – very interesting! It looks like this server might possibly be at risk for the Shellshock vulnerability, which FRSecure has written about in the past.
From the information gathered thus far, we have most likely identified a target with a vulnerability we may be able to exploit. The next step is to examine how we could successfully execute an attack, and we will cover that in next month’s article.
On that note, if you’re interested in playing along at home, download the virtual machine (which is pre-configured to be vulnerable), as well as a copy of Kali Linux. From there, we’ll go through everything together, step by step.
Conclusion
Conclusion? Hardly! We have identified our target and are ready to launch an attack, but next month is when the real fun starts. However, if you have questions at any point during this blog series, please do not hesitate to reach out via our contact form.






